【操作系统】Linux 中的 Page Cache
参考资料:
文件 I/O 简明概述 - page cache
进程写文件时,进程发生了崩溃,已写入的数据会丢失吗?
Linux Page Cache 调优在 Kafka 中的应用
【操作系统】一文带你深入浅出零拷贝技术
【操作系统】如何避免预读失效和缓存污染的问题?
一、引言
腾讯音乐三面的问题
用java写文件时,当向磁盘写文件时,写一半的时候如果进程崩了,文件里面会有数据吗。
大概就是,进程写文件(使用缓冲 IO)过程中,写一半的时候,进程发生了崩溃,已写入的数据会丢失吗?
答案,是不会的。
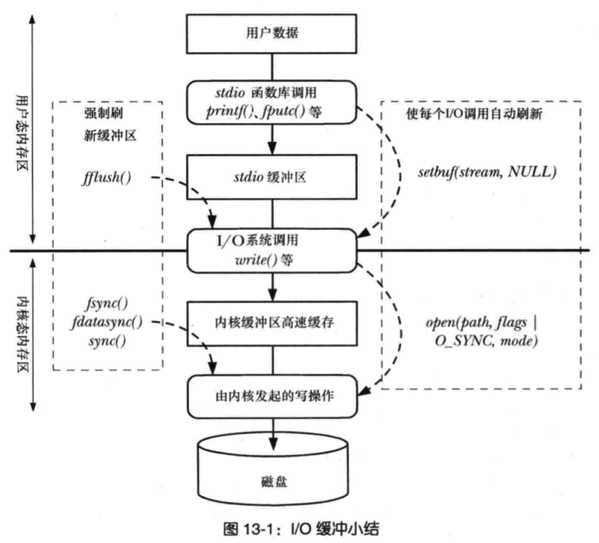
因为进程在执行 write (使用缓冲 IO)系统调用的时候,实际上是将文件数据写到了内核的 page cache,它是文件系统中用于缓存文件数据的缓冲,所以即使进程崩溃了,文件数据还是保留在内核的 page cache,我们读数据的时候,也是从内核的 page cache 读取,因此还是依然读的进程崩溃前写入的数据。
内核会找个合适的时机,将 page cache 中的数据持久化到磁盘。但是如果 page cache 里的文件数据,在持久化到磁盘化到磁盘之前,系统发生了崩溃,那这部分数据就会丢失了。
当然, 我们也可以在程序里调用 fsync 函数,在写文文件的时候,立刻将文件数据持久化到磁盘,这样就可以解决系统崩溃导致的文件数据丢失的问题。
二、Page Cache
2.1、Page Cache 是什么?
为了理解 Page Cache,我们不妨先看一下 Linux 的文件 I/O 系统,如下图所示:
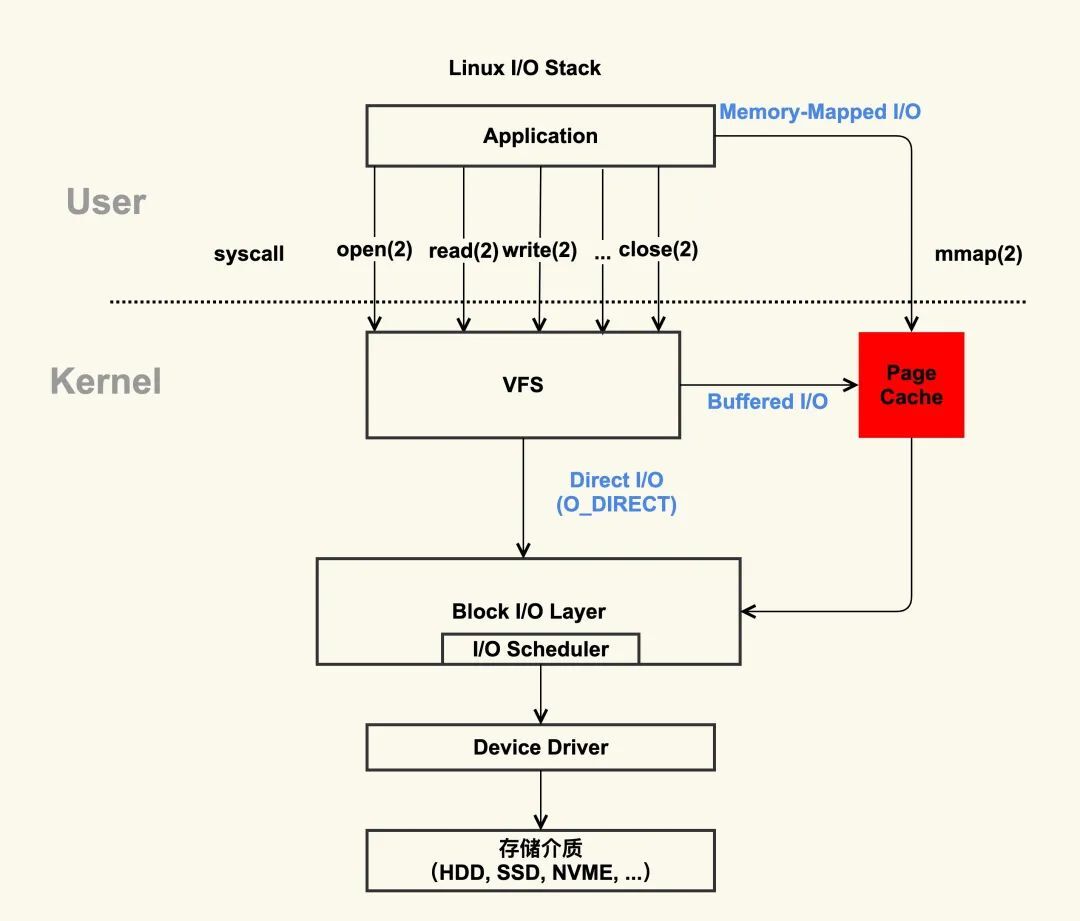
上图中,红色部分为 Page Cache。可见 Page Cache 的本质是由 Linux 内核管理的内存区域。我们通过 mmap 以及 buffered I/O 将文件读取到内存空间实际上都是读取到 Page Cache 中。
Page Cache是针对文件系统的缓存,通过将磁盘中的文件数据缓存到内存中,从而减少磁盘I/O操作提高性能。
对磁盘的数据进行缓存从而提高性能主要是基于两个因素:
- 磁盘访问的速度比内存慢好几个数量级(毫秒和纳秒的差距);
- 被访问过的数据,有很大概率会被再次访问。
文件读写流程如下所示:
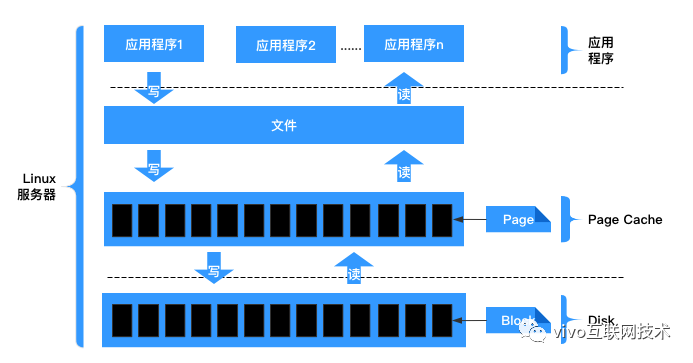
2.2、读Cache
当内核发起一个读请求时(例如进程发起read()请求),首先会检查请求的数据是否缓存到了Page Cache中。
如果有,那么直接从内存中读取,不需要访问磁盘,这被称为cache命中(cache hit);
如果cache中没有请求的数据,即cache未命中(cache miss),就必须从磁盘中读取数据。然后内核将读取的数据缓存到cache中,这样后续的读请求就可以命中cache了。
page可以只缓存一个文件部分的内容,不需要把整个文件都缓存进来。
2.3、写Cache
当内核发起一个写请求时(例如进程发起write()请求),同样是直接往cache中写入,后备存储中的内容不会直接更新(当服务器出现断电关机时,存在数据丢失风险)。
内核会将被写入的page标记为dirty,并将其加入dirty list中。内核会周期性地将dirty list中的page写回到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致。
当满足以下两个条件之一将触发脏数据刷新到磁盘操作:
- 数据存在的时间超过了dirty_expire_centisecs(默认300厘秒,即30秒)时间;
- 脏数据所占内存 > dirty_background_ratio,也就是说当脏数据所占用的内存占总内存的比例超过dirty_background_ratio(默认10,即系统内存的10%)的时候会触发pdflush刷新脏数据。
2.4、Swap 与缺页中断
Swap 机制指的是当物理内存不够用,内存管理单元(Memory Mangament Unit,MMU)需要提供调度算法来回收相关内存空间,然后将清理出来的内存空间给当前内存申请方。
Swap 机制存在的本质原因是 Linux 系统提供了虚拟内存管理机制,每一个进程认为其独占内存空间,因此所有进程的内存空间之和远远大于物理内存。所有进程的内存空间之和超过物理内存的部分就需要交换到磁盘上。
操作系统以 page 为单位管理内存,当进程发现需要访问的数据不在内存时,操作系统可能会将数据以页的方式加载到内存中。上述过程被称为缺页中断,当操作系统发生缺页中断时,就会通过系统调用将 page 再次读到内存中。
我们来看一下缺页中断的处理流程,如下图:
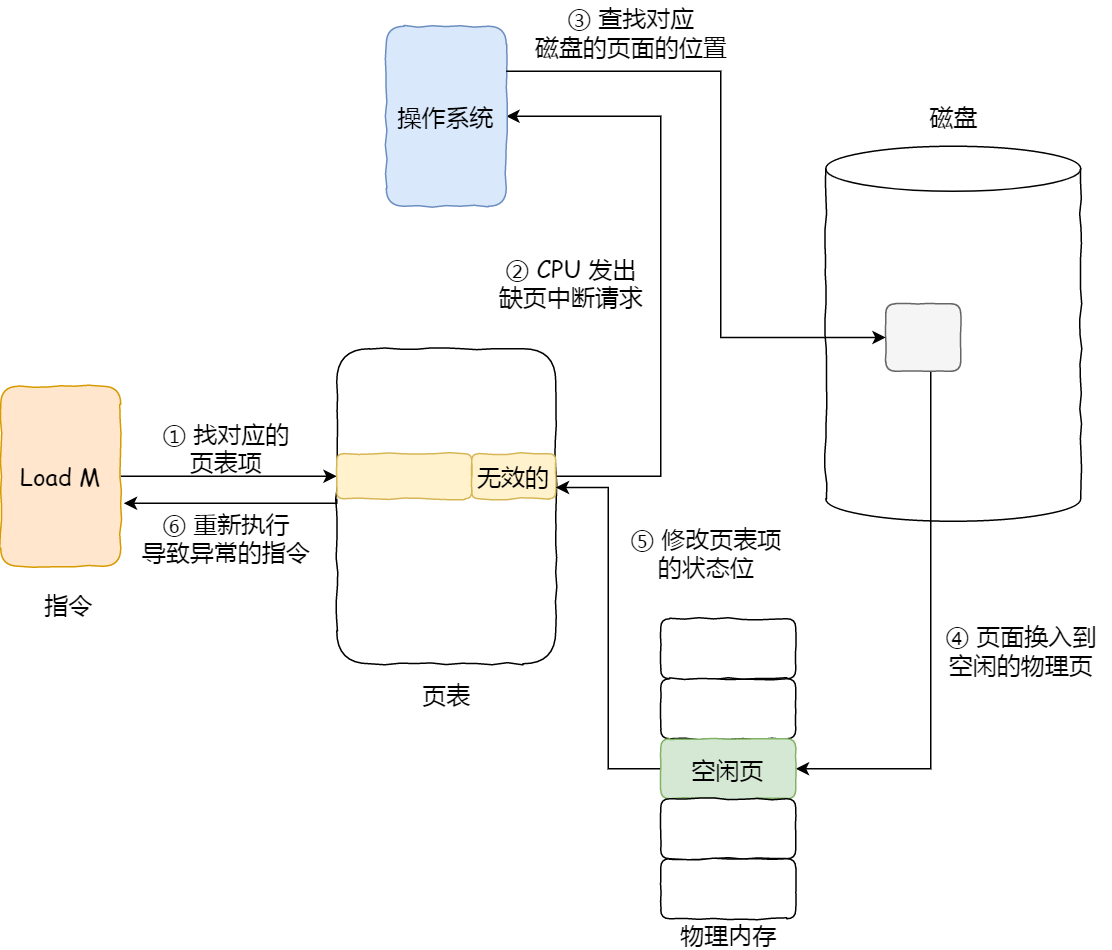
但主内存的空间是有限的,当主内存中不包含可以使用的空间时,操作系统会从选择合适的物理内存页驱逐回磁盘,为新的内存页让出位置,选择待驱逐页的过程在操作系统中叫做页面替换(Page Replacement),替换操作又会触发 swap 机制。
如果物理内存足够大,那么可能不需要 Swap 机制,但是 Swap 在这种情况下还是有一定优势:对于有发生内存泄漏几率的应用程序(进程),Swap 交换分区更是重要,这可以确保内存泄露不至于导致物理内存不够用,最终导致系统崩溃。但内存泄露会引起频繁的 swap,此时非常影响操作系统的性能。
Linux 通过一个 swappiness 参数来控制 Swap 机制:这个参数值可为 0-100,控制系统 swap 的优先级:
- 高数值:较高频率的 swap,进程不活跃时主动将其转换出物理内存。
- 低数值:较低频率的 swap,这可以确保交互式不因为内存空间频繁地交换到磁盘而提高响应延迟。
最后,为什么 SwapCached 也是 Page Cache 的一部分?
Page Cache 是 Linux 内核用于缓存文件系统数据和元数据的一种机制。SwapCached 则是 Linux 内核中用于缓存交换空间(swap space)中的页面的一种机制。尽管它们缓存的内容不同,但 SwapCached 也被视为 Page Cache 的一部分,这是因为它们都使用了相同的页面高速缓存机制,即 Linux 中的页缓存(page cache)。
当匿名页(Inactive(anon) 以及 Active(anon))先被交换(swap out)到磁盘上后,然后再加载回(swap in)内存中,由于读入到内存后原来的 Swap File 还在,所以 SwapCached 也可以认为是 File-backed page,即属于 Page Cache。这个过程如下图所示。
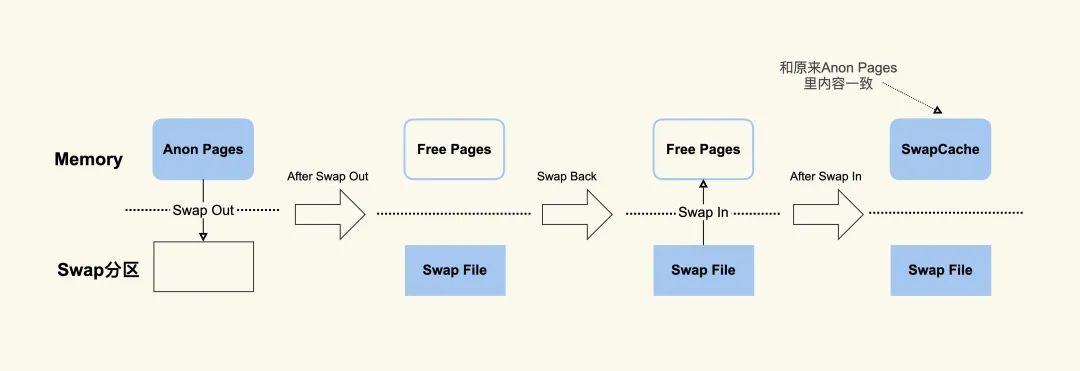
当系统需要将一个页面从内存中移除时,Linux 内核会优先考虑将 SwapCached 中的页面释放掉,这样可以避免频繁地读取交换空间中的数据而影响系统性能。如果系统需要更多的内存,则还可以通过释放 Page Cache 中的页面来腾出更多的可用内存。因此,将 SwapCached 视为 Page Cache 的一部分可以帮助操作系统更好地管理系统内存,提高系统性能。
2.5、Page Cache 与预读
操作系统为基于 Page Cache 的读缓存机制提供预读机制(PAGE_READAHEAD),一个例子是:
- 用户线程仅仅请求读取磁盘上文件 A 的 offset 为 0-3KB 范围内的数据,由于磁盘的基本读写单位为 block(4KB),于是操作系统至少会读 0-4KB 的内容,这恰好可以在一个 page 中装下。
- 但是操作系统出于局部性原理会选择将磁盘块 offset [4KB,8KB)、[8KB,12KB) 以及 [12KB,16KB) 都加载到内存,于是额外在内存中申请了 3 个 page;
下图代表了操作系统的预读机制:
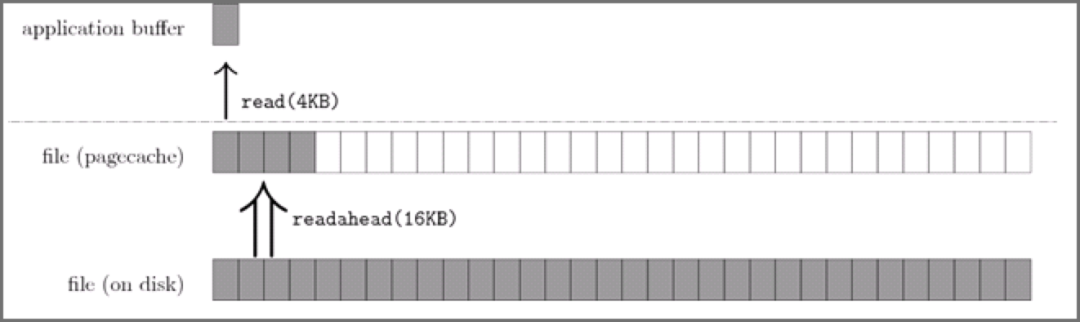
上图中,应用程序利用 read 系统调动读取 4KB 数据,实际上内核使用 readahead 机制完成了 16KB 数据的读取。
三、Page Cache 与文件持久化的一致性&可靠性
代 Linux 的 Page Cache 正如其名,是对磁盘上 page(页)的内存缓存,同时可以用于读/写操作。
任何系统引入缓存,就会引发一致性问题:内存中的数据与磁盘中的数据不一致,例如常见后端架构中的 Redis 缓存与 MySQL 数据库就存在一致性问题。
Linux 提供多种机制来保证数据一致性,但无论是单机上的内存与磁盘一致性,还是分布式组件中节点 1 与节点 2 、节点 3 的数据一致性问题,理解的关键是 trade-off:吞吐量与数据一致性保证是一对矛盾。
首先,需要我们理解一下文件的数据。文件 = 数据 + 元数据。元数据用来描述文件的各种属性,也必须存储在磁盘上。因此,我们说保证文件一致性其实包含了两个方面:数据一致+元数据一致。
文件的元数据包括:文件大小、创建时间、访问时间、属主属组等信息。
我们考虑如下一致性问题:如果发生写操作并且对应的数据在 Page Cache 中,那么写操作就会直接作用于 Page Cache 中,此时如果数据还没刷新到磁盘,那么内存中的数据就领先于磁盘,此时对应 page 就被称为 Dirty page。
当前 Linux 下以两种方式实现文件一致性:
- Write Through(写穿):向用户层提供特定接口,应用程序可主动调用接口来保证文件一致性;
- Write back(写回):系统中存在定期任务(表现形式为内核线程),周期性地同步文件系统中文件脏数据块,这是默认的 Linux 一致性方案;
上述两种方式最终都依赖于系统调用,主要分为如下三种系统调用:
| 方法 | 含义 |
|---|---|
| fsync(intfd) | fsync(fd):将 fd 代表的文件的脏数据和脏元数据全部刷新至磁盘中。 |
| fdatasync(int fd) | fdatasync(fd):将 fd 代表的文件的脏数据刷新至磁盘,同时对必要的元数据刷新至磁盘中,这里所说的必要的概念是指:对接下来访问文件有关键作用的信息,如文件大小,而文件修改时间等不属于必要信息 |
| sync() | sync():则是对系统中所有的脏的文件数据元数据刷新至磁盘中 |
上述三种系统调用可以分别由用户进程与内核进程发起。下面我们研究一下内核线程的相关特性。
- 创建的针对回写任务的内核线程数由系统中持久存储设备决定,为每个存储设备创建单独的刷新线程;
- 关于多线程的架构问题,Linux 内核采取了 Lighthttp 的做法,即系统中存在一个管理线程和多个刷新线程(每个持久存储设备对应一个刷新线程)。管理线程监控设备上的脏页面情况,若设备一段时间内没有产生脏页面,就销毁设备上的刷新线程;若监测到设备上有脏页面需要回写且尚未为该设备创建刷新线程,那么创建刷新线程处理脏页面回写。而刷新线程的任务较为单调,只负责将设备中的脏页面回写至持久存储设备中。
- 刷新线程刷新设备上脏页面大致设计如下:
- 每个设备保存脏文件链表,保存的是该设备上存储的脏文件的 inode 节点。所谓的回写文件脏页面即回写该 inode 链表上的某些文件的脏页面;
- 系统中存在多个回写时机,第一是应用程序主动调用回写接口(fsync,fdatasync 以及 sync 等),第二管理线程周期性地唤醒设备上的回写线程进行回写,第三是某些应用程序/内核任务发现内存不足时要回收部分缓存页面而事先进行脏页面回写,设计一个统一的框架来管理这些回写任务非常有必要。
Write Through 与 Write back 在持久化的可靠性上有所不同:
- Write Through 以牺牲系统 I/O 吞吐量作为代价,向上层应用确保一旦写入,数据就已经落盘,不会丢失;
- Write back 在系统发生宕机的情况下无法确保数据已经落盘,因此存在数据丢失的问题。不过,在程序挂了,例如被 kill -9,Page Cache 中的数据操作系统还是会确保落盘;
四、Page Cache 的优劣势
4.1、Page Cache 的优势
1.加快数据访问
如果数据能够在内存中进行缓存,那么下一次访问就不需要通过磁盘 I/O 了,直接命中内存缓存即可。
由于内存访问比磁盘访问快很多,因此加快数据访问是 Page Cache 的一大优势。
2.减少 I/O 次数,提高系统磁盘 I/O 吞吐量
得益于 Page Cache 的缓存以及预读能力,而程序又往往符合局部性原理,因此通过一次 I/O 将多个 page 装入 Page Cache 能够减少磁盘 I/O 次数, 进而提高系统磁盘 I/O 吞吐量。
4.2、Page Cache 的劣势
page cache 也有其劣势,最直接的缺点是需要占用额外物理内存空间,物理内存在比较紧俏的时候可能会导致频繁的 swap 操作,最终导致系统的磁盘 I/O 负载的上升。
Page Cache 的另一个缺陷是对应用层并没有提供很好的管理 API,几乎是透明管理。应用层即使想优化 Page Cache 的使用策略也很难进行。因此一些应用选择在用户空间实现自己的 page 管理,而不使用 page cache,例如 MySQL InnoDB 存储引擎以 16KB 的页进行管理。


![[架构之路-204]- 常见的需求分析技术:结构化分析与面向对象分析](https://img-blog.csdnimg.cn/9355ae02c9ff42418f8d5f87968c690d.png)